Words of notice: This is an article I wrote for Gekko. Many thanks for their consent to sharing this story here.
The right architecture for the right need
Over the last few years, we have observed a steady growth of compute-layer services that natively integrate cost-efficiency, operational excellence, performance, security and reliability. These services are the same that development teams leverage in order to spend more time on their products and less time tweaking infrastructure and connecting pipes. Among these services are AWS Lambda, AWS Fargate and its companion services AWS ECS and AWS EKS.
It is no surprise that each compute layer has its strengths and weaknesses. The general trend to rely on Serverless however is a healthy sign of transformation, as it requires organizational readiness and a deep understanding of a Cloud provider’s offering in multiple angles. With some exceptions, any solution can be divided into services which would run in leaner and isolated environments. Keep in mind that this process is not inevitable, rather the contrary: not every application needs to run in AWS Lambda. Excellent and efficient software architectures are still as relevant today, if not more!
While there has been a push to develop Serverless-native applications, operational requirements grew exponentially which fostered an ecosystem of technologies supporting development and platform engineering teams in order to simplify this sudden shift in complexity from code to infrastructure for many projects. Starting out with Serverless is challenging and leads to a significant amount of misunderstanding and inefficiencies. This loss of control may lead teams to turn their backs on these offerings and slow down transformation; it is a form of risk aversion.
DevOps transformation
As a Cloud and DevOps Engineer myself, my mission is manyfold. That said, one of my most common set of challenges is building foundational infrastructure using identified Infrastructure as Code, Continuous Integration and Continuous Deployment or Delivery blocks. As a classic example, my most requested stack is an Amazon API Gateway + AWS Lambda + Amazon DynamoDB backend with an Angular frontend hosted on Amazon S3 + Amazon CloudFront, all provisioned using the most recent version of Terraform.
Each project of this sort requires platform engineering teams to prepare a repository, invite the relevant users, create a deployment IAM Role for each AWS account to deliver the app to. Each IAM Role contains similar permissions for resources named almost identically since they follow a naming convention. For development teams, it requires learning to use the same technologies albeit to a shallower extent. Finally, the code to provision the desired infrastructure contains API definitions, Infrastructure as Code, CI/CD definitions that are just slightly different on a project per project basis and thus almost identically copied.
The developer in me believes that reducing duplicates can lower the setup and update time for similarly specced projects. Even better: it can significantly increase the level of “self-serviceness” of the infrastructure thanks to the reduction of personnel to mobilize before writing the first line of code!
This belief is shared by AWS in the form of AWS Proton. This service could awkwardly be described as the AWS Service Catalog for development teams, where you would choose the toolkit that would get the project started and prepare its final architecture from the get-go! Only the underlying resources provisioned by AWS Proton are charged; the service itself is free.
If this announcement cheers you up, then it would be wise checking out the official blog post which is also a step-by-step guide on how to get started.
Dive in
As a word of caution, if you wish to use AWS Proton, keep in mind that it is subject to specific terms of service due to its Preview status. Furthermore, you would still need to understand, create and maintain AWS CloudFormation templates, AWS CodePipeline and AWS CodeBuild configurations, AWS IAM roles and policies, etc.
If you are familiar with all these technologies, then you might have an idea of how they could interact: some repository actions would start a CI/CD which checks out the repository, tests and packages the application according to given procedures and deploys it.

Side-by-side AWS Proton and project configurations
Here is an example: the AWS Proton template
developed by platform engineering teams and DevOps and one service using the template,
where development teams and DevOps trade ideas that tighten the integration of their new solution with AWS. An example
can be seen in /specs/svc-spec.yaml in the template repository. This file contains the pieces of information an
authorized user would have to fill when requesting this specific service in the AWS Proton interface or through the CLI.
Note the unit test and packaging commands. Now read the /Makefile in the solution code; the test and install steps
are defined there.
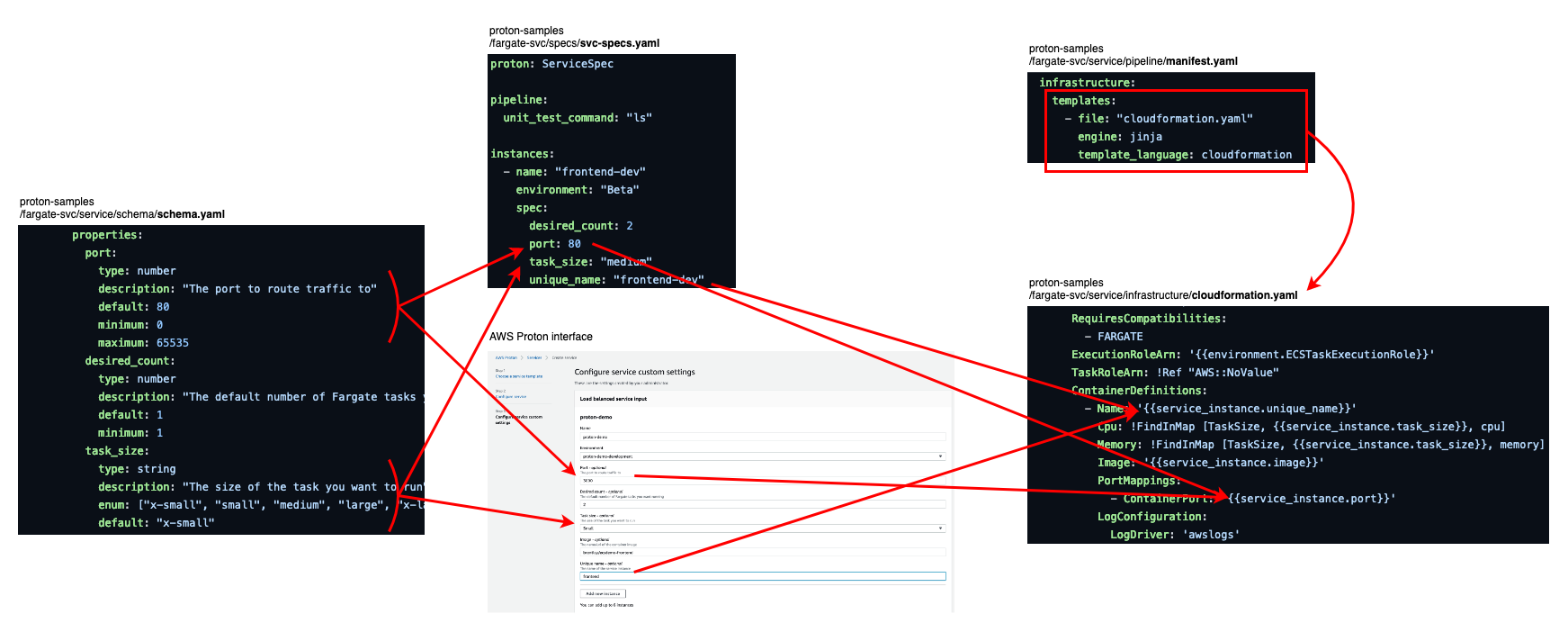
From AWS Proton specification to AWS CloudFormation template
What magic allows us to define these fields? Schemas and templates! Since the same AWS CloudFormation template may be
used for different solutions, it must contain variables. These variables need to be defined, documented and displayed.
manifest.yaml files throughout the template repository indicate that the templates indeed contain variables.
service/schema/schema.yaml, certainly the most critical Schema of this repository, defines the same
unit_test_command and packaging_command variables, which you have encountered in /specs/svc-spec.yaml a few
moments ago.
From there, with some practical knowledge of AWS CloudFormation, you may be able to piece back the resources that are
provisioned, their attributes, etc. As for the service_instance and pipeline variables, they are fed by AWS Proton
itself, according to the Administration guide.
There is nothing that stands out in this service, which is a good thing if your wish is to get started as soon as
possible.
Your turn now
Meta-services open new opportunities to administrators, platform engineering teams and development teams. AWS Proton is a strong candidate to become a central hub where teams meet, paving the way towards low-overhead self-service projects and driving up the adoption of the Cloud therefore the transformation of the organization while not losing sight of lower layer resources maintenance for platform engineering teams. As one project becomes this easy to start now, why not starting more?
If this preliminary introduction to this new offering has captured your interest, the next step is to get started with AWS Proton’s documentation.