Words of notice: This is an article I wrote for Gekko. Many thanks for their consent to sharing this story here.
There are many different storage types in the wild and they each have specifics that make them suitable for defined sets of use cases.
Regardless of the scale, storage poses challenging issues. For instance Brewer’s theorem, also known as the CAP theorem, states that designing distributed data stores requires trade-offs. Simply put, in case of a write failure on a storage system due to internal network conditions, would it be preferable to drop the operation or to attempt to process it anyway? The first would guarantee consistency as the system becomes predictable while the second guarantees availability as everything is processed to a certain degree. Of course this also applies to read operations.
Long live eventual consistency
There is a common misconception that Amazon S3 stores files and directories. That is not true: Amazon S3 addresses stored data as objects. There is no directory, consequently the storage system hierarchy is flat. In fact, we could compare Amazon S3 to a key-value datastore where the key portion would be the object “prefix”, i.e. its path and its value would be the object contents.
On the subject of objects: unlike files, they are indivisible. If one needs to edit one character in a very large object, the whole object must be replaced.
Amazon S3 is key to a large range of use cases: static web assets, low-cost storage and archival, analytics, datalakes, etc. Still, because of the highly distributed nature of the service, some cases required more effort as some behaviors were not completely predictable. In fact, some operations patterns were treated as “eventually consistent”, which means that they would eventually reach the desired state.
This known unknown has been a major pain point, especially for projects heavily relying on Amazon S3’s capabilities. Here are four example scenarios that sum up the old consistency model:
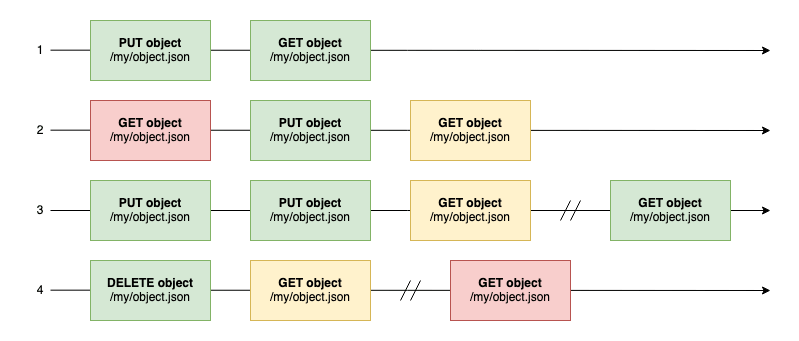
Old consistency model scenarios
Scenario 1 is expected: a new object can be retrieved immediately after its creation. What if it is queried first,
like in scenario 2? Then Amazon S3 may have responded with an error or with the new object’s content.
Scenario 3 happens when an object is updated multiple times in quick successions. Immediately requesting the updated
object may have returned one of the previous versions and would eventually return the last.
Finally, scenario 4 was similar to scenario 3 in the sense that a deletion followed by a query may have returned the
object in its previous state, followed by the updated version a few moments later.
Projects sitting on top of S3 had to create a layer to absorb these sorts of behaviors and expose a more predictable interface. This involved thousand of lines of code using other adjacent services to store states and metadata, like S3Guard.
For this reason, the teams behind Amazon S3 decided to tackle this issue. The challenge comes from how widespread this service is. Customers expect their projects to behave “identically but better” after such an update. One of the ways to achieve this goal was to get closer to communities developing critical tools around S3 like S3A, a connector between Hadoop and Amazon S3. Both teams collaborated to make this connector ready in preparation for a consistency model change, as stated in the related blog post from AWS.
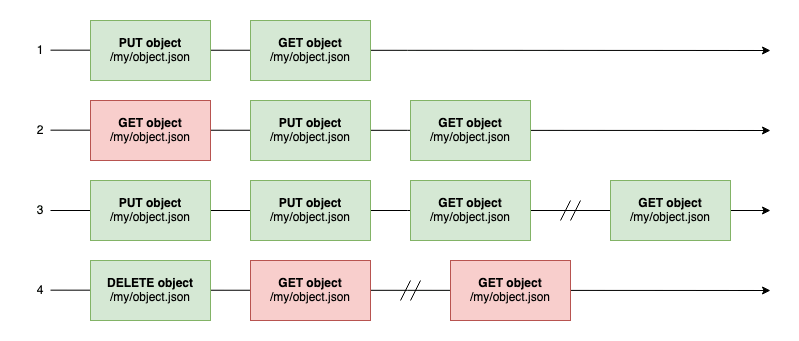
New consistency model scenarios
Situations where the result was indeterminate in the old consistency model now have a response. This new model implements “strong consistency”, which means that reading an object just after it has been updated returns its new contents! Scenarios 2, 3 and 4 demonstrate that updates to the object are taken into account when chaining Write and Read requests, even when they are preceded by a Read like scenario 2. But is this the whole story? Applications sometimes exchange asynchronously and concurrently with Amazon S3. How does this update affects these cases?
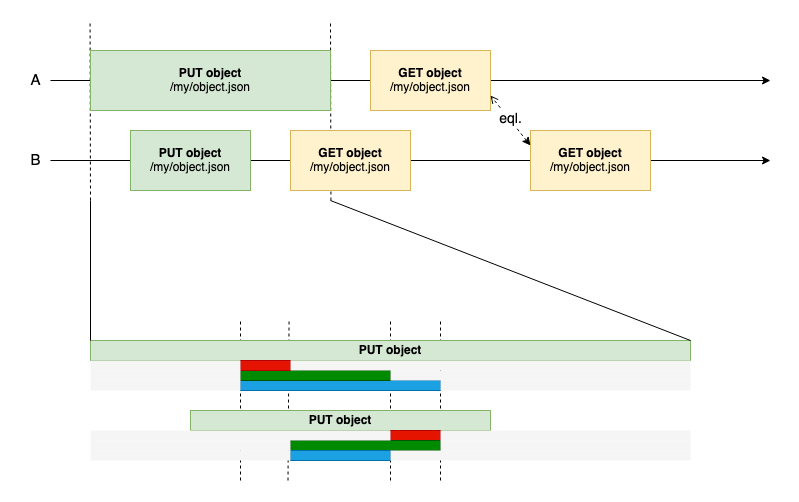
Concurrent S3 updates
Two administrators are browsing a back-office application and update the same content. A is subject to bad network conditions while B benefits from a fast and reliable connection. There is no way to predict what the Read operations return; even though network conditions differ, both requests have reached Amazon S3 at roughly the same moment and Amazon S3 applies a last-writer-wins strategy on content updates as stated in the documentation.
The zoomed in timeline explores three scenarios where A goes first. The same scenarios apply if B goes first. Whether A overlaps B entirely (Blue), partially (Green) or not at all (Red) is not visible by the application. This can however influence the first Read response received by B: if A has not completed yet, B may receive its own version due to the strong consistency model. However, we know the other two Read responses will be identical since both Writes will be processed by that point. In other words: in the eventuality of concurrent updates of the same object, the only way to find out which version has been persisted is to perform a Read after all Writes have completed. Consequently, strong consistency also adds some degree of predictability to concurrent scenarios.
If you wish to learn more about this change and how it may affect you, read the announcement or the Strong consistency feature page for Amazon S3. To discover more storage announcements, check out the AWS Blog!