Words of notice: This is an article I wrote for Gekko. Many thanks for their consent to sharing this story here.
Throughout their services, AWS uses a special type of sharding called “Shuffle sharding” to virtually isolate each customer while colocating their resources. The most visible example, the one mentioned in the Amazon Builders’ Library, concerns Route 53 and how each DNS zone gets assigned four of the 2048 virtual shards created by AWS for the service. There are 700B+ possible combinations of those shards and the number of combinations grows exponentially with the number of virtual shards and the number assigned to each DNS zone.
What situation does “shuffle sharding” prevents? When one customer undergoes an attack that visibly impacts their services. Colocating a set of customers on the same physical infrastructure would spread issues to all of them if one misbehaves.
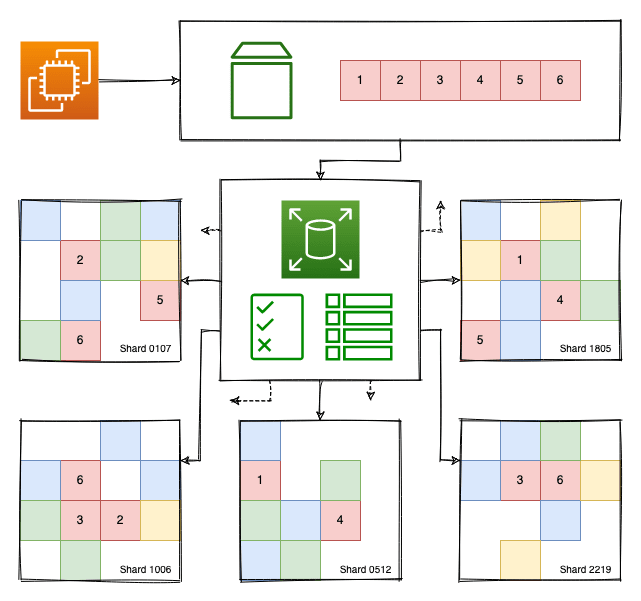
Shuffle sharding for EBS
The colored diagram above shows an EC2 instance with an EBS volume attached and how the actual data is stored in different shards. For simplicity, not all of them are displayed and there is no mention of encryption here. In this model, the individual block can be tracked and assigned to a random combination of disks. All of them would need to fail at the same time for data to be lost.
If multiple customers were assigned the same hardware and one overused their share the others would be impacted. By assigning random disks on volume creation, this creates a layer of isolation but hosting workloads requires disks with enough free space and changing disks whenever a resize becomes impossible. Not a practical solution at scale.
Since these disks are used in block storage situations, it is possible to split the volume into blocks that may be larger than the ones an EC2 instance uses and assign them random shards, which would map to disk portions. This solves the free space and resizing issues, provided the status of the shards and the locations of each block in the system are tracked. This design can be incremented upon with encryption and access control! What happens when one physical disk fails, though?
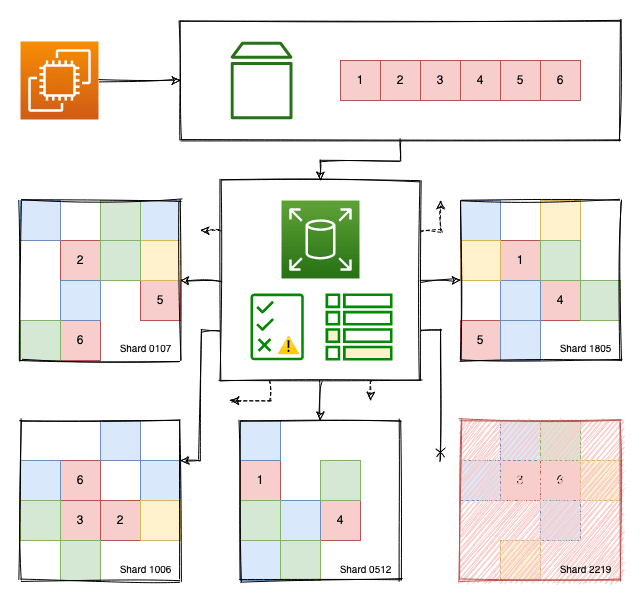
KO disk in EBS backend
One disk failed. The service endpoint keeps a note on the status of the related shards and trivially redirects requests to healthy ones. Nevertheless, if all the shards connected to the same volume are suddenly offline this could become a major outage, except that… each volume has quotas and burst capacity and the service endpoint evenly balances the load between multiple shards so that the wear is predictable and disk usage is optimal. Even then, remember to backup your volumes!
Speaking of quotas, IOPS optimized and general purpose Amazon EBS volumes have received major updates! Read on to learn more about that.
IO -extra- optimized
A few years ago, a database administrator that knew my passion for extreme performance sent me a research article and an advertisement on the topic of large relational databases. The advertisement contained a synthetic benchmark mentioning millions of database transactions per second in a single piece of hardware.
These kinds of workloads are not a clear cut for the Cloud: dedicated specialized bare-metal hardware with highest-performance everything to fully benefit from that hardware. With no obvious way to do this, it could be wise to provide these features in a more generic fashion, like high-speed networking and storage capabilities with high-end instances.
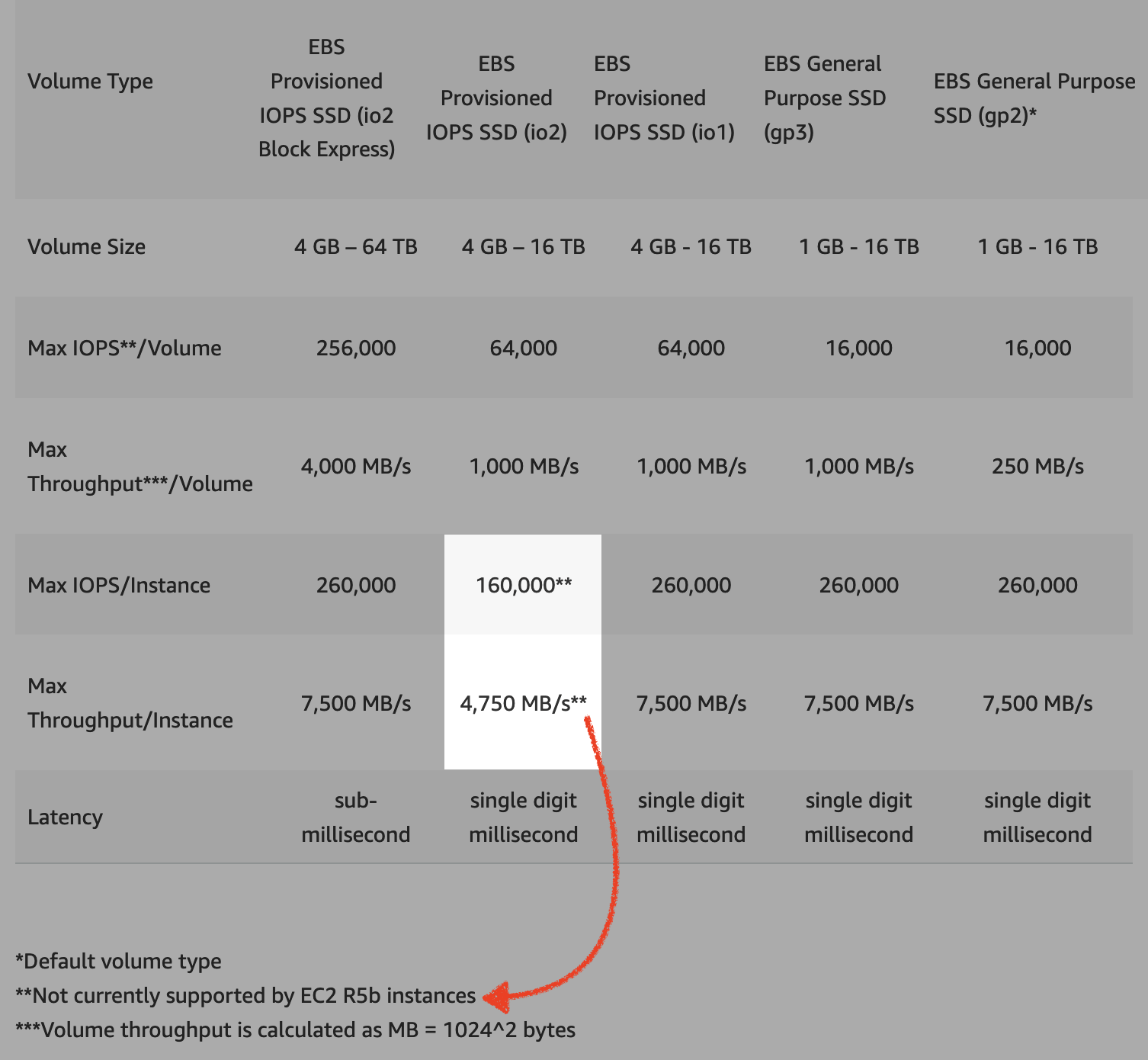
The new EBS SSD line-up with a focus on io2
With the release of Amazon EBS io2 volumes earlier this year, building durable high-end storage systems became more cost-effective than ever. With a few asterisks: at the time of writing, an io2 volume is still limited to 64k IOPS and 1000 MB/s throughput. Moreover, the maximum 260k IOPS of the R5b instance family, released in December of 2020, cannot be reached. This generation increases the durability by one nine and the IOPS per GiB, which avoids storage overprovisioning to reach the maximum performance for a volume.
Most of these issues have been resolved with a new Amazon EBS volume offering: io2 Block Express! Currently in Preview, these volumes obsolete having multiple high-performance EBS volumes attached to the same Amazon EC2 instance in order to reach the maximum performance for an Amazon EC2 instance, even for the R5b family! What’s more is that thanks to the Elastic Fabric Adapter, which is the network brick allowing HPC workloads to run on AWS, a volume can reach 4x the IOPS, 4x the throughput and 4x the storage size with sub-millisecond latencies and low jitter.
Remember the cost-effectiveness argument of io2? io2 Block Express goes beyond by doubling the IOPS per GiB and decreasing the cost of provisioned IOPS between 64k and 256k. io2 Block Express is therefore even more cost-effective and significantly reduces complexity.
If you want to learn more about io2 Block Express, then the announcement blog post is what you need. There are a few caveats to account for since this feature is currently in Preview.
gp3, truly customizable
As the name might suggest, general purpose volumes are the middle-ground in AWS. As such, any new feature will have far reaching ripple effects on the Cloud community, let alone a new volume generation! This time, the newly announced volume type is gp3.
gp3 changes habits: there is no 100 IOPS baseline then 3 IOPS per GiB starting from 33.33 GiB with the ability to burst to 3k IOPS for extended periods of time. 3k IOPS is the new baseline as is 125 MB/s throughput. Additional IOPS and throughput can be provisioned independently. This comes with a 20% storage cost decrease compared to gp2, which makes gp3 appealing to replace gp2 volumes and some io1 and io2 volumes too!
The legitimacy of increasing IOPS and throughput independently come from multiple reasons:
- There is a formula linking throughput to IOPS:
IOPS * average IO size = throughput; - IOPS counted towards the quota may differ from IOPS submitted by the OS. Amazon EBS merges contiguous operations into one and splits random operations as per the documentation.
Because the IO size is optimized by AWS, it is possible to reach one of the limits long before reaching the other depending on your workloads.
On the subject of gp2 vs. gp3, Cloudwiry wrote a blog post comparing costs between those volume types and it comes out that the upgrade from gp2 is sensible in every possible situation.
Finally, to optimize EBS usage, AWS Compute Optimizer now supports EBS volume recommendations! Modifying the go-to volume type for the EC2 instances seems like the best time to upgrade the price-performance ratio of an infrastructure.
In a nutshell
While the perfect storage solution does not exist, this set of releases allows AWS customers to benefit from the latest technological breakthroughs. Breakthroughs unlock new use cases and new use cases bring new exciting challenges to solve.
If all these storage game changers convinced you to hack into your infrastructure, then it is worth checking out the AWS Blog for more exciting announcements!